Axual Documentation
Welcome to the Axual documentation. Use the menu on the left to navigate through the various sections.
What’s new in Axual 2025.3?
In the fall release of Axual Platform, exciting new features are introduced:
-
All changes on Cluster, Environment, Topic and Application resources are audited and viewable by the Tenant Admin. In addition, auditing has been extended to include Group, Instance, and Schema resources with comprehensive action tracking:
-
Instance: Schema Registry Configured, Schema Registry Unconfigured, Cluster Added, Cluster Removed, KSML Provisioner Configured, KSML Provisioner Unconfigured
-
Schema: Schema Version Uploaded, Schema Version Deleted, Schema Ownership Transferred
-
Group: Created, Updated, Deleted. Read more here.
-
-
KSML 1.1.0 integration in the Self-Service brings fine-grained SSL/SASL Broker authentication options and enhanced Schema Registry support with support for Confluent and Apicurio SerDes, plus new JsonSchema and Protobuf capabilities. See KSML release notes and Read more about how to Enable KSML in Self-Service.
-
Improved the Group page on the Self-Service to show the group members and all the resources that are owned by the Group.
-
Many improvements and bug fixes improve the stability and usability of the platform and Self-Service.
Read more about the latest platform release in our Release Notes or in our Release Blog
Support
| For urgent production issues, we are on standby 24/7 to answer your questions. Please use the standby number communicated to you. |
For non-urgent requests, you’ll find our support options here.
Getting Started
As soon as you understand the basic concepts, and you want to get started building your application, creating a schema, or just want a guide to follow along to, please refer to the Getting started section.
Why Data Streaming is Crucial in Modern Systems Compared to Batch Processing
Data is generated everywhere—by people, devices and applications. From a bank transfer to a car approaching a garage entrance, to an energy meter reporting usage, data is constantly being created.

But the real value of this data lies not just in its storage, but in its immediate use. For instance, you want your banking app to show a transaction as soon as it happens, or the garage door to open as you approach.
Traditional approaches like batch processing may be slow, processing data in intervals, which can delay actions.
This is where data streaming becomes essential.
Real-Time Data Utilization
In contrast to older batch processing methods, where data is collected and processed at set intervals, data streaming allows for real-time data processing.
Events are captured and made available instantly. Whether it’s detecting a fraudulent bank transfer or processing an energy bill as soon as the reading is captured, streaming data enables businesses to act when the event is happening, offering a significant advantage over delayed batch processing.
Reducing Redundant Processes
Another key benefit of data streaming is its efficiency in reusing data. In traditional systems, APIs or database queries might be repeatedly called to fetch the same information, leading to inefficiencies and delays. Streaming data ensures that the data is accessible to multiple consumers at the same time, allowing different applications to use it as soon as it’s generated without repeated requests. This asynchronous communication not only speeds up the process but also reduces the load on systems.
Decoupling Producers and Consumers
In a streaming architecture, data producers (like sensors or applications) generate events and push them to the platform, without needing to know who will use the data.
Similarly, consumers (applications or services) can subscribe to data streams they’re interested in and react to those events in real-time.
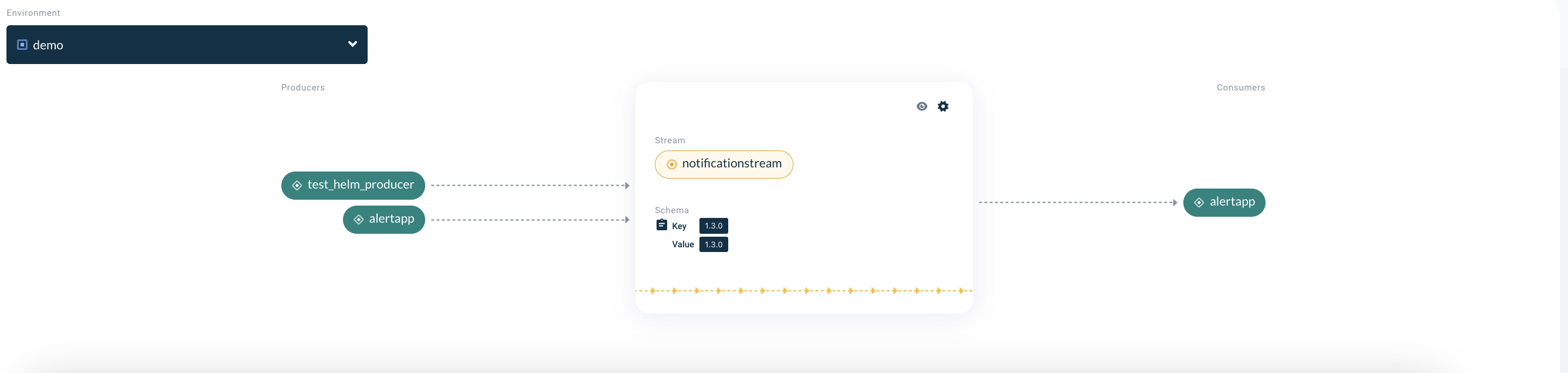
This decoupling of producers and consumers creates a more flexible system, where data can be used by multiple services without requiring tight integration, as is often necessary in traditional batch systems.
Speaking The Same Language: Schemas
Producers might not care about who is reading their messages; they need to speak in a language understood by the other party, the consumers.
In other words, the messages they produce to a data stream need to adhere to a specific schema, comparable to an API specification or a database table structure.
You might conclude that there isn’t a decoupling between producer and consumer, strictly speaking, because they need to agree on what schema to use for messages on a particular data stream. This is only partly true; producers are allowed to change schemas considering the backward compatibility of the schemas.
High Availability and Scalability
Data streaming platforms are designed to handle the high velocity and volume of real-time data, offering scalability and stability.
Unlike batch systems that might struggle with spikes in data or system failures, streaming platforms ensure that data is always available and that systems can continue to operate without disruption.
Support for Reactive Patterns
Streaming data naturally supports reactive patterns, where systems respond to events as they happen. This flexibility allows consumers to process events at their own pace, a contrast to the rigid structure of batch processing. As a result, streaming data can often replace traditional request-response communication, creating more efficient, event-driven systems.
In summary, while older approaches like batch processing have their place, data streaming is crucial for modern systems that require real-time, scalable, and flexible data processing. It allows organizations to act instantly on critical data, making their operations more responsive, efficient, and future-proof.